วันนี้เรามาสร้างรูปแรกจาก Stable Diffusion กันดีกว่า แต่ก่อนจะเริ่ม ผมอยากให้พวกเราได้รู้จัก และเข้าใจเครื่องมือ การตั้งค่าต่างๆ ที่จำเป็น และใช้งานบ่อย (เรียกว่าต้องสนใจทุกครั้งที่เจนรูปก็ได้) เพราะถ้าคุณเริ่มจากความเข้าใจ คุณก็จะไปต่อในขั้นตอนต่อไปได้ดี เชื่อผมนะ ผมมั่วมาก่อน เสียเวลามากมาย ฮ่าาา
เรามาเริ่มต้นเจนรูปกันเลยดีกว่า หลังจากที่คุยให้ฟังเรื่องการ เช่าใช้งาน Stable Diffusion จากเว็บ RunDiffusion ในราคาชั่วโมงละ 17 บาท ไปก่อนหน้านี้ สำหรับการแนะนำการใช้งานในวันนี้ก็จะเป็นการใช้งานกับทางเว็บ RunDiffusion นะครับ แต่หน้าตาและคำสั่งต่างๆ ก็จะเหมือนกันไม่ว่าเราจะใช้งานจาก PC ส่วนตัว หรือติดตั้งบน Google Colab ก็ตาม เพราะมันก็คืออินเตอร์เฟส หรือ Web-ui ตัว Automatic1111 ตัวเดียวกันนั่นหละครับ
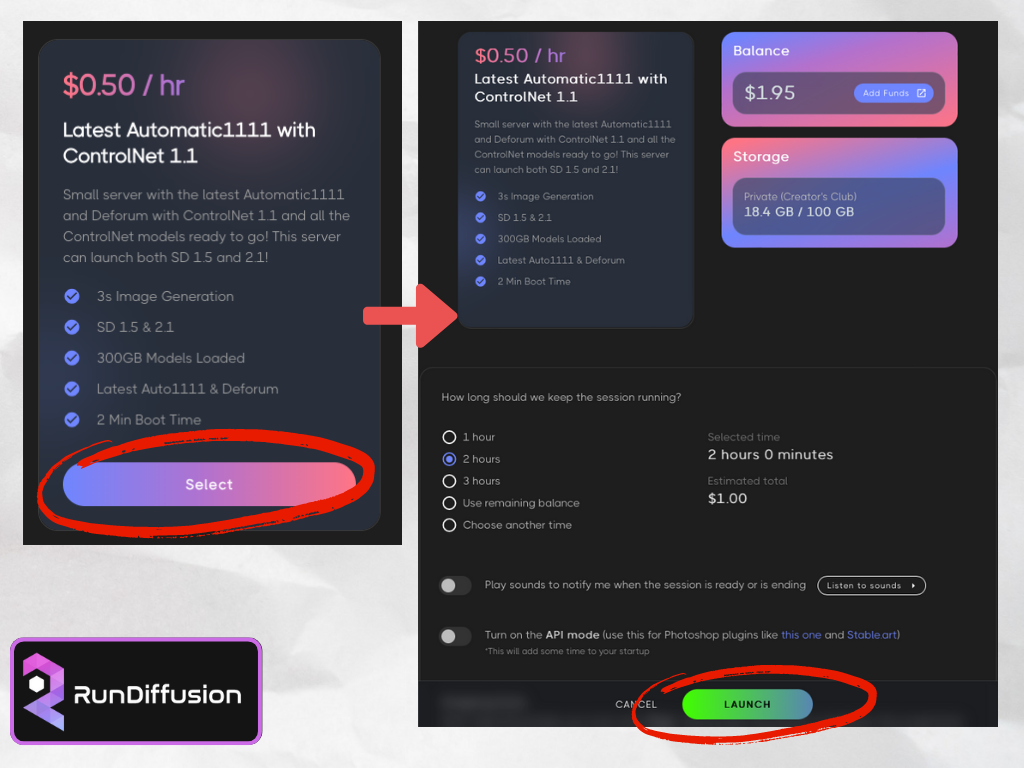
วันนี้เราจะเริ่มจากการใช้งาน Small Tier (Package เริ่มต้น) ในราคาชั่วโมงละ 17 บาท หรือ $0.50 กัน ให้เราคลิก Select จากนั้นก็เจอหน้าจอที่บอกว่า เงินที่เราเติมในระบบเหลืออยู่เท่าไหร่ และเราจะใช้เวลาเท่าไหร่ในการใช้งาน ตรงนี้เลือกเท่าไหร่ก็ได้นะครับ เพราะว่าเราจะหยุดใช้เมื่อไหร่ก็ได้ ค่าใช้จ่ายนับเป็นนาที แค่ว่าถ้าเราเลือกแบบเจาะจงเวลาอย่างเช่น 1 ชั่วโมง ระบบก็ทำการแจ้งเตือนเราตอนที่ใกล้จะหมดเวลาเท่านั้นเอง และถ้าเรายังทำงานไม่เสร็จ เราสามารถกดต่อเวลาได้เลย เริ่มต้นใช้งานกดปุ่ม LAUNCH ได้เลย
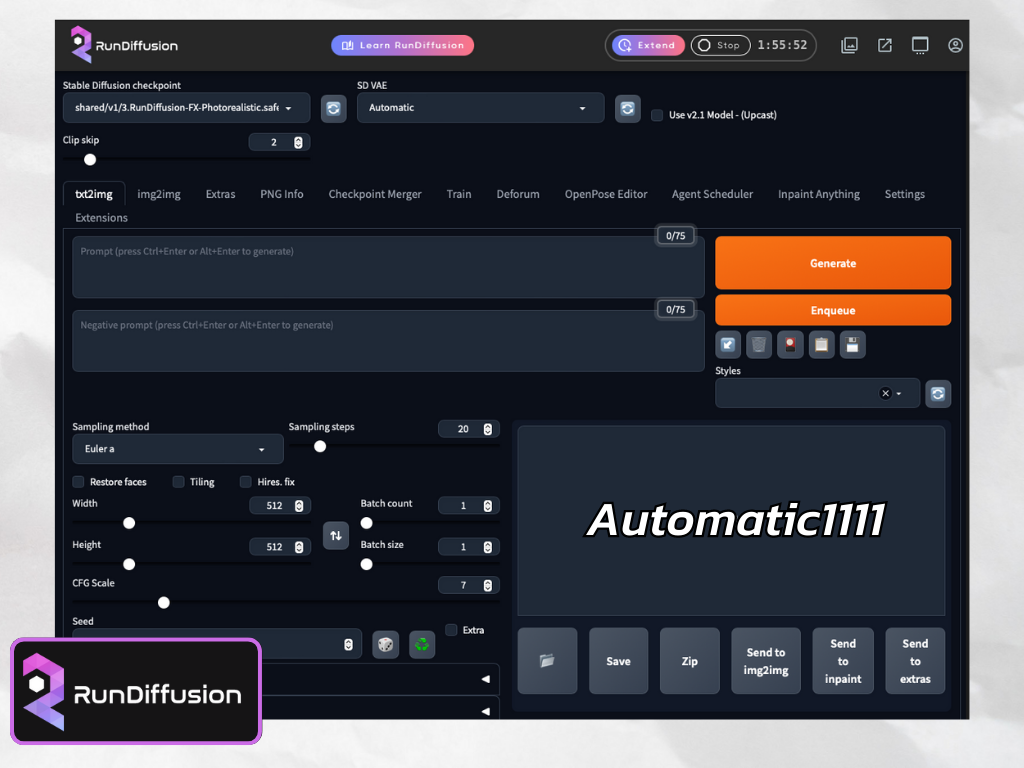
หลังจากที่เรียกใช้งาน Stable Diffusion web-ui จะใช้เวลาโหลดประมาณ 1-2 นาที ช่วงนี้จะลุกไปเดิมน้ำ ปัสสวะ หรือยืดเส้นยืดสายรอก็ได้ เมื่อโหลดเสร็จ เราจะเจอหน้าจอที่มีหน้าตาแบบนี้ เอาจริงๆ ตอนแรกที่ผมเริ่มศึกษาเรื่องนี้ ผมรู้สึกว่าหน้าจอรกๆ ของมันเนี่ย ช่างน่ากลัวเหลือเกิน อะไรบ้างก็ไม่รู้ ยุบยับไปหมด แต่พอได้อยู่กับมันสัก 4-5 ชั่วโมง ความคุ้นเคยก็เกิดขึ้น และเริ่มดีขึ้นเรื่อยๆ ที่อยากจะบอกก็คือ สำหรับใครที่เพิ่งเริ่มต้น เห็นหน้าจอของมันแล้วก็อย่าพึ่งวิ่งหนีไปไหนนะครับ อะไรที่เป็นเรื่องใหม่สำหรับเรา ครั้งแรกมันก็จะรู้สึกยากเสมอ ให้เวลากับมันหน่อย
เครื่องมือและการตั้งค่าเบื้องต้น ที่เราต้องรู้
สำหรับวันนี้เราเริ่มต้นแบบง่ายๆ สิ่งแรกเราต้องทำความรู้จักกับเครื่องมือหลักๆ ที่มีผลต่อรูปภาพที่เราสร้างกันก่อน ซึ่งก็มีอยู่ไม่กี่ตัว เราจะลองตั้งค่าต่างๆ ไปพร้อมกับการสร้างรูปง่ายๆ เราจะได้เข้าใจมากยิ่งขึ้น (หวังว่าจะเป็นอย่างนั้นนะ ฮ่า)
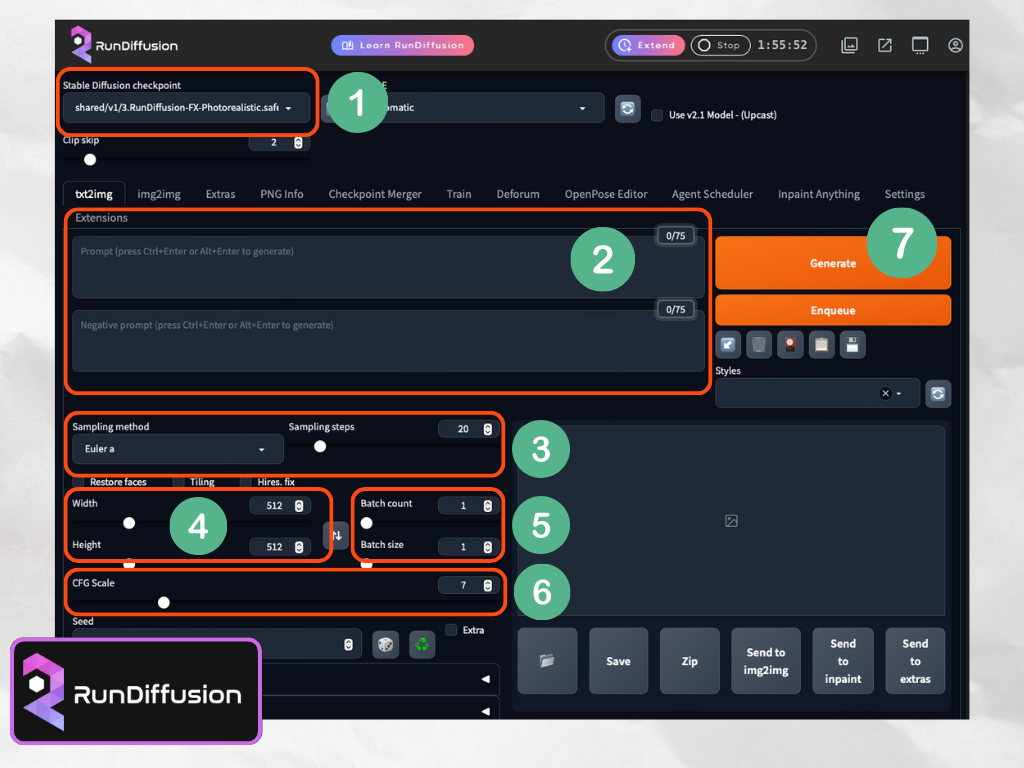
1. Checkpoint
Checkpoint หรือ Models หลัก อันนี้จะได้ยินพูดถึงกันบ่อยๆ เลย เข้าใจง่ายๆ มันคือ Theme หลักของงานที่เราทำการสร้าง เราอยากได้แนว Animated หรือการ์ตูนญี่ปุ่นสวยๆ เราก็ต้องใช้งาน Checkpoint ที่สร้างและออกแบบมาเพื่อ Animated , หรือเราอยากได้ภาพที่เป็นคนเหมือนจริง แบบ Realistic จริงๆ ก็ต้องเลือก Checkpoint ที่ถูกออกแบบมาแบบนั้นเหมือนกัน ถึงจะได้งานตรงอย่างที่ใจเราต้องการ
ตอนนี้มีคนทำ Checkpoint ออกมาให้เลือกใช้เยอะมากๆ เราสามารถที่จะไปดาวน์โหลดเพื่อเอามาติดตั้งใช้งานได้ หลายๆ Checkpoint เราอาจจะคุ้นเคย เพราะเป็นการ ก๊อปปี้ลายเส้น รูปแบบงานของศิลปินชื่อดังมาใช้ ทำให้ Ai เจนรูปใหม่ๆ ที่เหมือนกับตัวศิลปินคนนั้นๆ ทำออกมาเอง ตรงนี้เลยเป็นเรื่องที่ต้องระวัง เพราะมันสามารถที่จะกอปปี้อัตลักษณ์ ลายเส้น ชิ้นงาน คนอื่นออกมาได้อย่างแนบเนียน (อาจจะเข้าข่ายเป็นการละเมิดลิขสิทธิ์ เรื่องนี้ยังคลุมเครือ ยังไงต้องติดตามดูกันต่อไปครับ)
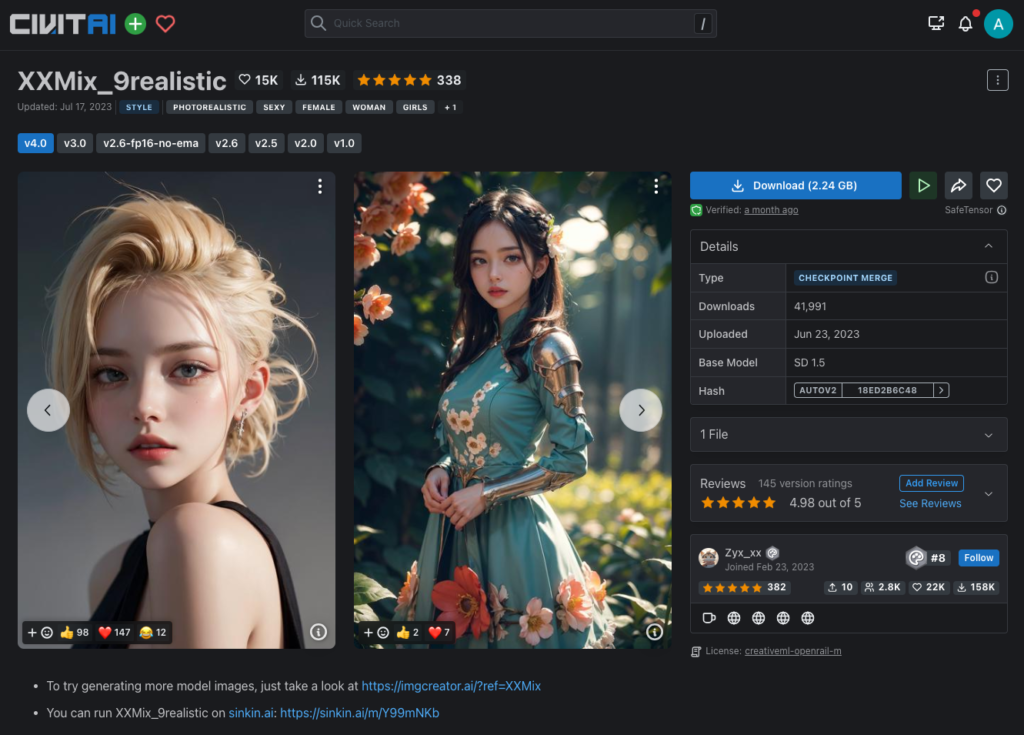
เพื่อให้เข้าใจมากขึ้น สามารถที่จะเข้าไปดูตัวอย่างรูปที่เจน หรือสร้างจาก Checkpoint แต่ละตัวได้ในเว็บ Civitai.com และเรายังสามารถดาวน์โหลด Checkpoint ในเว็บนี้มาใช้งานได้ด้วยนะครับ
2. Prompt และ Negative Prompt
Prompt เป็นส่วนที่สำคัญมาก เป็นส่วนที่เราต้องใช้ทักษะภาษาอังกฤษเพื่อที่จะบรรยายภาพที่เราอยากได้ ให้ตัว AI ได้รู้ และมันจะได้สร้างภาพให้ออกมาอย่างที่เราตั้งใจ Prompt จะมีอยู่สองส่วนด้วยกัน
Prompt ปกติ คือส่วนหลักที่บอกไปก่อนหน้านี้ เราต้องการอะไรก็อธิบายเป็นภาษาอังกฤษไปให้ AI ได้รู้
Negative Prompt ตรงนี้คือเราไม่อยากให้รูปเรามีอะไรโผล่ออกมา ก็ให้เราใส่เอาไว้ในส่วนนี้
(เดี๋ยวเราจะมาดูตัวอย่างการเขียน Prompt กัน แต่ตอนนี้ผมจะขอแนะนำให้พวกเราได้รู้จักเครื่องมือที่จำเป็นให้ครบกันก่อนนะครับ)
3. Sampling Method และ Sampling Steps
Sampling Method ตัวนี้จะมีให้เราเลือกใช้งานหลายตัวเลย ซึ่งตรงนี้ผมก็บอกไม่ได้เหมือนกันนะ ว่าควรจะเลือกอะไร เพราะแต่ละตัวก็จะมีผลให้ภาพที่สร้างขึ้นมาแตกต่างกันไป ในการเริ่มต้นให้ลองใช้งาน 2 ตัวนี้ดูนะครับ (ไม่ได้ว่าดีที่สุดนะครับ มันขึ้นอยู่กับว่าเราชอบผลลัพธ์แบบไหนด้วย เพราะแต่ละคนจะมีความชอบต่างกันไป 2 ตัวที่แนะนำคือตัวที่ผมใช้บ่อยเฉยๆ น้าา) Euler a และ DMP++ 2M SDE Karras
และในอนาคตก็อาจจะมีตัวใหม่ๆ ตามมาอีกด้วยนะครับ อันนี้เราต้องลองเทสดูครับ ว่าเราชอบแบบไหน
Sampling Steps ตัว Sampling Steps เป็นการตั้งค่าว่าจะให้ Sampling Method ที่เราเลือกตะกี้ ทำงานกี่ steps ซึ่งตรงนี้ผมคงไม่สามารถอธิบายว่ามันมีการทำงานอย่างไร เพราะผมก็ไปไม่ถึงตรงนั้นเหมือนกัน แต่อยากจะบอกให้ฟังง่ายๆ ว่า ถ้าตั้งค่าน้อยเกินไปภาพที่ได้จะดูเหมือนทำไม่เสร็จ ไม่สวย ดูไม่ออก แต่ถ้าตั้งค่าสูงเกินไป ภาพก็จะดูเยอะเกินไป เหมือนมีการทำงานซ้ำๆ ทับลงไปในภาพหลายรอบ มีคำแนะนำจากหลายๆ ที่ที่น่าเชื่อถือ ว่าควรตั้งอยู่ระหว่าง 20-60 และเหมือนเดิม คุณต้องเป็นคนที่ลองทดสอบดูว่า ค่าเท่าไหร่ที่เหมาะสมที่คุณจะได้ภาพที่ต้องการ ใกล้กับสิ่งที่คุณคิดเอาไว้ที่สุด
*ค่าต่างๆ เหล่านี้จะมีความสัมพันธ์กันหมด ตั้งแต่ Checkpoint การ เลือกใช้ Sampling Method และค่า Sampling Steps หมายความว่าถ้าได้ภาพที่ดีจากจาก Checkpoint ตัวหนึ่ง พอเปลี่ยน Checkpoint อีกตัว อาจจะไม่ดีเหมือนเดิม ต้องเปลี่ยน Sampling Method และ Sampling steps ให้เหมาะสมอีกที
4. ขนาดภาพ Width Height
ค่าเริ่มต้นจะเป็น 512×512 อาจจะรู้สึกว่าทำไมขนาดมันจุ๋มจิ๋มจังเลย แต่อย่าเพิ่งรีบปรับขนาดให้ใหญ่โตตั้งแต่ทีแรกที่เริ่มเจนภาพนะครับ ทำความเข้าใจตรงนี้กันก่อน การเจนรูปของ Stable Diffusion v1.5 ได้รับการ train มาด้วยขนาด 512×512 และใน V2.1 (ล่าสุดในตอนที่เขียนเนื้อหานี้) ถูกเทรนมาในขนาด 768×768 ซึ่งหมายความว่า เราควรเริ่มเจนภาพในขนาดที่ไม่ใหญ่กว่าขนาดที่ระบบถูกเทรนมามากจนเกินไป ขนาดสูงสุดในการเจนครั้งแรกไม่ควรเกิน 768×1024 หรือ 1024×768 เพราะถ้าเกินจากนี้ เราอาจจะได้เห็นตัวละครเราเป็นคนสองหัว สามมือ สี่ขา ผิดที่ผิดทางแบบในตัวอย่างที่ผมให้ดูนี้ก็ได้ครับ
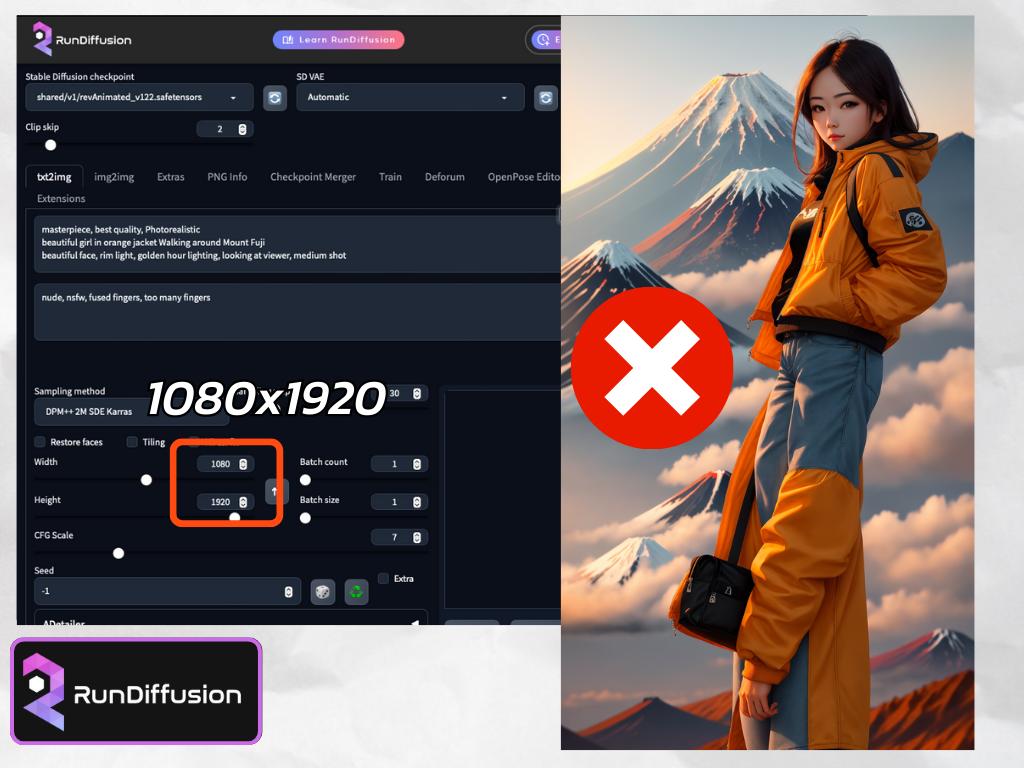
จากที่นั่งอ่านในกลุ่ม Stable Diffusion Thailand คนเก่งๆ หลายๆ ท่านจะเริ่มต้นทำงานจากขนาดภาพเล็กก่อน และหลังจากที่ได้ภาพที่ใกล้เคียงกับความต้องการแล้ว ก็จะมีกระบวนการในการปรับแต่ง (Controlnet, img2img) และขยายขนาดภาพให้ใหญ่ขึ้นในขั้นตอนต่อๆ ไป ซึ่งเราจะค่อยๆ เรียนรู้กันในตอนต่อๆ ไปนะครับ
5. Batch count และ Batch size
Batch count คือจำนวนรอบที่คุณต้องการให้ AI เจนภาพออกมาให้ จากการกด generate หนึ่งครั้ง
Batch size คือจำนวนภาพที่จะได้ต่อครั้งที่ Batch count ทำงาน เช่น
- ถ้าเราตั้งค่า Batch count เป็น 1 และ Batch size เป็น 4 ระบบทำงาน 1 รอบ จะได้ออกมา 4 ภาพ
- ถ้าเราตั้งค่า Batch count เป็น 2 และ Batch size เป็น 4 ระบบทำงาน 2 รอบ จะได้ออกมา 8 ภาพ
- ถ้าเราตั้งค่า Batch count เป็น 4 และ Batch size เป็น 1 ระบบทำงาน 4 รอบ จะได้ออกมา 4 ภาพ
ซึ่งถ้าใส่จำนวน Batch size เยอะ การ์ดจอเราต้องแรงระดับนึงด้วยนะครับ เพราะการทำงานแต่ละรอบแล้วต้องเจนหลายรูปต้องการพลังงานค่อนข้างเยอะ ถ้าเอาแบบเซฟๆ ก็ใส่ Batch count 4 Batch size 1 ก็ได้ครับ แต่รอนานนิดนึง
6. CFC Scale
CFC Scale จะเป็นค่าที่กำหนดว่า เราจะให้ความสำคัญกับ Prompt ที่เราเขียนบอก AI มากน้อยขนาดไหน โดยที่ค่าน้อยๆ AI ก็จะให้ความสำคัญกับ Prompt เราน้อย และจะคิดแทนเราซะเยอะ ภาพที่ได้จะไม่ค่อยตรงกับสิ่งที่เราบอกเอาไว้ใน Prompt เท่าไหร่ แต่ก็อาจจะทำให้เราได้ไอเดียใหม่ๆ ที่ AI ช่วยคิดก็ได้ครับ
ตรงนี้เป็นคำแนะนำจากเว็บ RunDiffusion ซึ่งจากประสบการณ์ที่ใช้งาน SD มาอาทิตย์กว่าๆ ผมคิดว่าเป็นคำแนะนำที่ดีเลย
- CFG 2 – 6: ให้ความสำคัญกับ Prompt ของเราน้อย ภาพที่ได้จะไม่เหมือนกับที่เราตั้งใจ แต่อาจจะได้ไอเดียอะไรดีๆ กลับมา
- CFG 7 – 10: เป็นค่าที่ดูเหมาะสมดี ส่วนใหญ่เราจะใช้กันอยู่ประมาณ 7-10 นี่แหละครับ
- CFG 10 – 15: ใช้ในกรณีที่เราระบุความต้องการใน Prompt แบบยาวเหยียด ละเอียดมากๆ และอยากได้ภาพที่ออกมาตามที่เราได้ระบุเอาไว้
- CFG 16 – 20: ไม่แนะนำ เว้นแต่ในบางกรณี (อันนี้ไม่แน่ใจเหมือนกันนะครับ)
- CFG >20: ภาพที่ได้แทบจะใช้ไม่ได้เลย
7. Generate
ตรงนี้ก็คือปุ่มสั่ง เจน หรือสร้างรูปนั่นเองครับ
ได้เวลามาเจนรูปกัน!!
เริ่มต้นเรามาโฟกัสกันที่เรื่อง Prompt กันก่อนดีกว่า เพราะเป็นสิ่งที่สำคัญที่สุด ว่าภาพที่เราต้องการได้จาก AI เนี่ย จะออกมาอย่างที่เราต้องการได้ขนาดไหน ก็จะอยู่ที่ Prompt เป็นหลักเลย ตัวอย่างของเราในวันนี้ ผมอยากจะสร้างภาพของ
“สาวสวยใส่แจคเก็ตสีส้ม เดินออกกำลังอยู่แถวๆ ภูเขาไฟฟูจิ”
เอาง่ายๆ แบบนี้ก่อนนะครับ แต่ Prompt ที่ใช้ต้องเป็นภาษาอังกฤษ ไม่ต้องกังวลไปครับ ภาษาผมก็แย่พอกัน ผมก็เอาไปเข้า google translate เป็น eng แล้วค่อยเอามาใส่ในช่อง Prompt ก็จะได้เป็น
“beautiful girl in orange jacket Walking around Mount Fuji”
มาดูที่ Negative Prompt กันบ้าง อย่างที่บอกไปตอนแนะนำ ตรงนี้อะไรที่เราไม่อยากให้ออกมาในรูป เราใส่มันให้หมดนะครับ เช่นเราไม่ต้องการภาพโป๊ เปลือย (ถ้าไม่ใส่มีโอกาสออกมาสูงมากๆ ไม่ดีๆ) เราก็จะใส่คำว่า nude, nsfw (ย่อมาจาก Not safe for work ความหมายคือ ไม่ปลอดภัยถ้าเปิดดูในที่ทำงาน มันคือภาพโป๊นั่นแหละ) ถ้าเราไม่ต้องการให้นิ้วมือเกิน เพราะ AI เจนรูปส่วนใหญ่จะทำเรื่องนิ้วมือได้ค่อนข้างแย่ เราก็ใส่กันเอาไว้ก่อนเลยครับ อย่างคำว่า fused fingers, too many fingers
สรุป Negative Prompt เราจะใส่กันประมาณนี้ก่อนนะครับ “nude, nsfw, fused fingers, too many fingers”
ทีนี้เรามาเลือก checkpoint กัน สำหรับวันนี้เราจะใช้สองตัวที่มีความแตกต่างกันที่ค่อนข้างชัดเจนเราจะได้เห็นภาพ และเข้าใจเรื่องการเลือก checkpoint หรือ Models หลักกันมากยิ่งขึ้น เริ่มต้นให้เราเลือกเป็น XXMix_9realistic ซึ่งเราสามารถเข้าไปดูรายละเอียดการตั้งค่าเบื้องต้นได้จากหน้าเว็บ Civitai.com
**สำหรับในการใช้งาน SD ผ่าน RunDiffusion เนี่ย เค้ามี Checkpoint หลักมาให้ค่อนข้างเยอะ ประหยัดเวลาการติดตั้งไปได้เยอะเลย
การตั้งค่าต่างๆ ผมจะใช้ตั้งค่าดังนี้นะครับ และจะใช้ค่านี้ในทุกๆ รูปที่ทำ
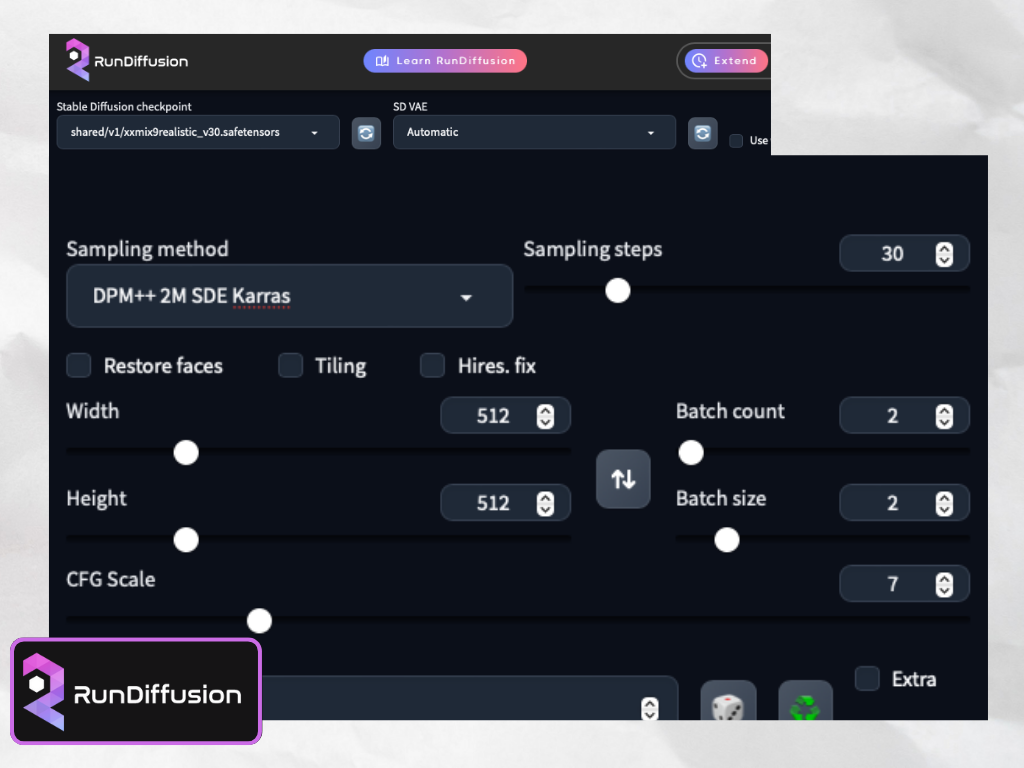
ตั้งค่าต่างๆ แล้วก็เอา Prompt ไปใส่ได้เลย
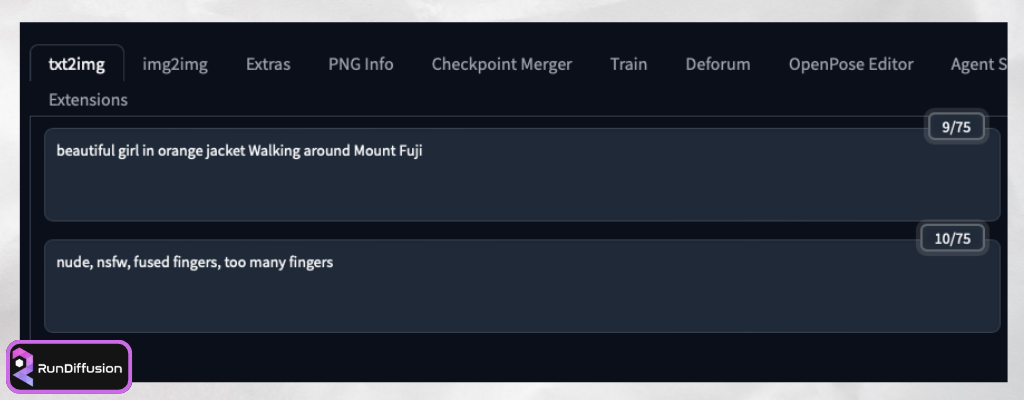
มาดูภาพที่ได้กันครับ
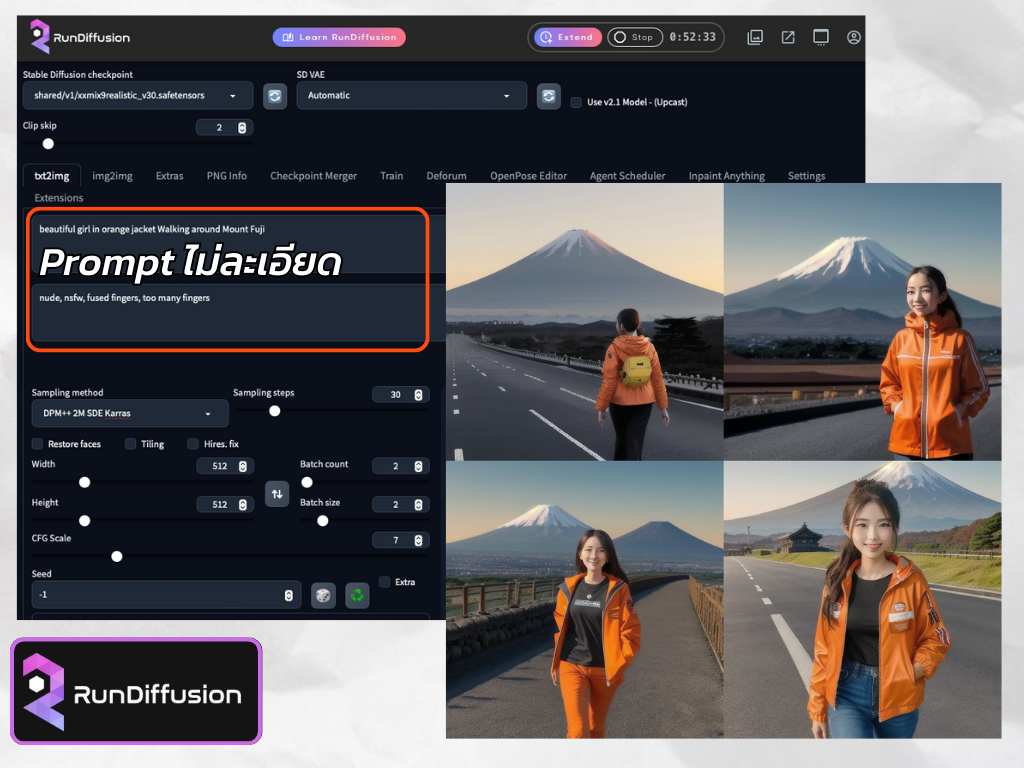
จะเห็นว่าภาพที่ได้ก็ตรงตามที่เราป้อนคำสั่ง Prompt ไปอยู่เหมือนกัน แต่ภาพไม่ค่อยจะสวยเท่าไหร่
ทีนี้เราลองเพิ่มคำศัพท์ ที่เกี่ยวกับความสวยของหน้าตา beautiful face
ลักษณะของแสงที่อยากได้เข้าไป rim light, golden hour lighting
บอกให้ตัวแบบมองคนดู (ไม่อยากให้หันหลัง) looking at viewer
และระบุขนาดภาพของหญิงสาวเป็นภาพถ่ายครึ่งตัว ซึ่งเราจะใช้ศัพท์ทางการถ่ายภาพว่า medium shot
beautiful girl in orange jacket Walking around Mount Fuji
beautiful face, rim light, golden hour lighting, looking at viewer, medium shot
ต่อไปจะเพิ่มคำศัพท์ยอดนิยม ที่คนส่วนใหญ่ชอบใส่กัน และเป็นเรื่องของคุณภาพรูปที่จะได้ อย่าง masterpiece, best quality, Photorealistic และผมจะเอาวางไว้ที่บรรทัดแรกเลย เพราะโดยปกติ SD จะให้ความสำคัญ Prompt จากซ้ายไปขวา และบนลงล่าง
Prompt ใหม่ที่เราจะเอาไปใช้ต่อไปจะเป็นชุดนี้นะครับ สำหรับ Negative Prompt ปล่อยเป็นอันเดิมไปเลย
masterpiece, best quality, Photorealistic
beautiful girl in orange jacket Walking around Mount Fuji
beautiful face, rim light, golden hour lighting, looking at viewer, medium shot
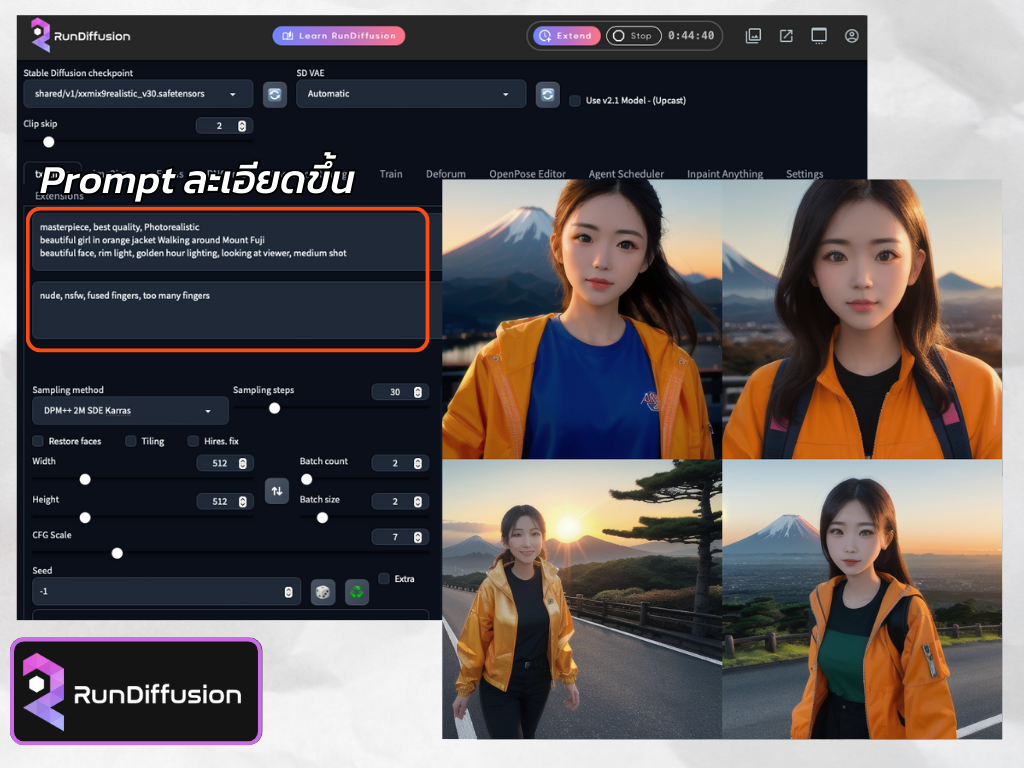
จะเห็นว่าภาพที่ได้ ดีขึ้นกว่า Prompt แรกที่มีบรรทัดเดียวเยอะเลยใช่ไหมครับ ทั้งเรื่องใบหน้าตัวแบบที่สวยขึ้น และแสงเงาต่างๆ ในภาพก็ดูดี มีมิติมากขึ้นด้วย

มาลองเปลี่ยน Checkpoint หรือ models หลักเป็นแนวการ์ตูน หรือ Animate กันดีกว่าครับ ผมเลือกเป็นตัวนี้ RevAnimated_v122 ดูรายละเอียด Civitai.com ผมจะใช้ Prompt และทุกการตั้งค่าเหมือนเดิมเลยนะ มาดูผลลัพธ์ที่ได้กัน
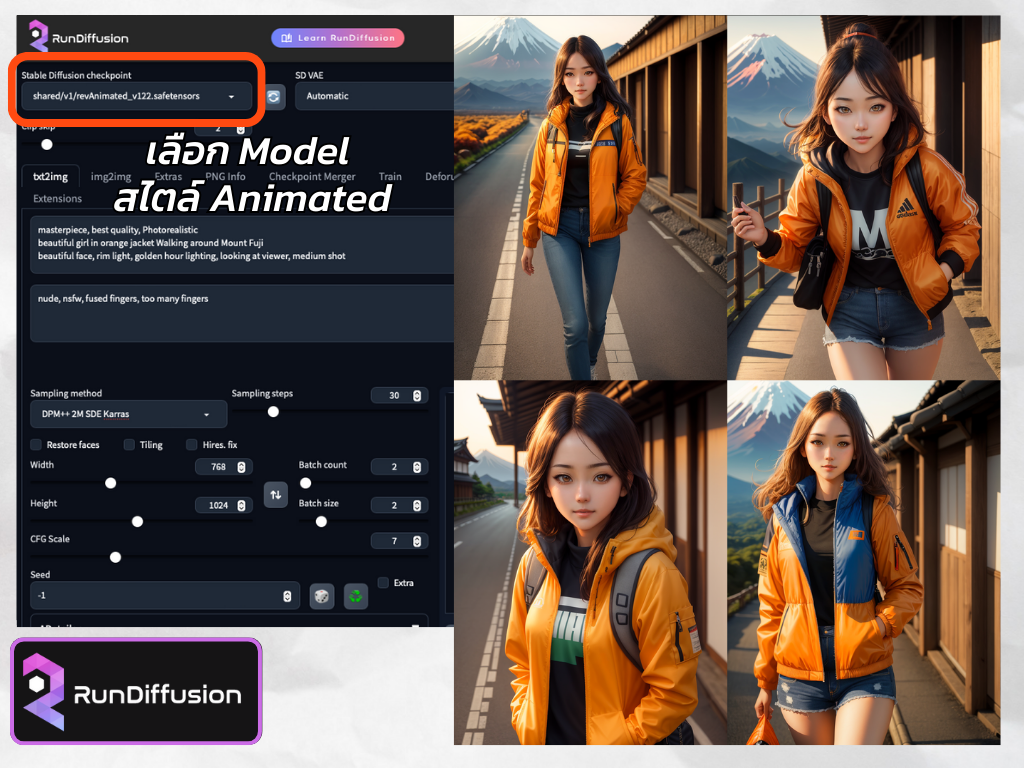

เรียบร้อยครับ เราจะเห็นว่าการเขียน Prompt เป็นอะไรที่สำคัญมากๆ เลยนะครับ เดี่ยวตอนต่อไปผมจะเขียนเรื่องของ Prompt เรื่องเดียวเลย ให้มือใหม่เข้าใจง่ายๆ เพราะว่ามันยังมีอะไรมากกว่าที่เราใช้งานกันวันนี้อีกเยอะครับ แต่ไม่ต้องกลัวน้าา อย่างที่เคยบอก เรียนรู้เรื่องใหม่ๆ ช่วงแรกมันก็รู้สึกว่ายากเป็นธรรมดา
ทีนี้ผมอยากจะให้พวกเราได้เห็นผลงานขั้นสุดยอดจากคนเก่งๆ ที่สร้างมาจาก Stable Diffusion กันบ้าง เดี๋ยวเห็นแค่ตัวอย่างที่ผมทำให้ดูแล้วจะคิดว่า ไม่เห็นจะสวย ไม่เห็นจะเจ๋งตรงไหนเลย แล้วจะหนีไปทำอย่างอื่นกันซะก่อน



สวยงามมากๆ เลยใช่ไหมครับ แน่นอนนะครับว่ายังมีเทคนิคต่างๆ ที่เราต้องเรียนรู้ และต้องเข้าใจอีกเยอะ ผมก็ยังเป็นมือใหม่เรื่องนี้มากๆ เหมือนกัน อาศัยว่าเรียนรู้แล้วพยายามเขียนวิธีการต่างๆ เอาไว้ช่วยจำ และอยากจะทำเอาไว้เป็นคู่มือให้ลูกสาวผมที่ผมคิดว่าอีกไม่นานเธอน่าจะสนใจเรื่องนี้ได้ลองทำตามง่ายๆ
ถ้าเพื่อนๆ อ่านมาถึงตรงนี้ นั่นก็แสดงว่าน่าจะสนใจการสร้างภาพด้วย Stable Diffusion แน่นอน เรียนรู้ไปด้วยกันนะครับ ขอบคุณที่ติดตาม และถ้ามีผิดพลาดประการใด แจ้งได้นะครับ จะได้รีบแก้ไข เจอกันตอนต่อไป ขอบคุณครับ